定时库APScheduler
定时库APScheduler
简介
apscheduler 使用起来十分方便。提供了基于日期、固定时间间隔以及crontab 类型的任务,我们可以在主程序的运行过程中快速增加新作业或删除旧作业,如果把作业存储在数据库中,那么作业的状态会被保存,当调度器重启时,不必重新添加作业,作业会恢复原状态继续执行。apscheduler 可以当作一个跨平台的调度工具来使用,可以做为 linux 系统crontab 工具或 windows 计划任务程序的替换。注意,apscheduler 不是一个守护进程或服务,它自身不带有任何命令行工具。它主要是要在现有的应用程序中运行,也就是说,apscheduler 为我们提供了构建专用调度器或调度服务的基础模块。
基本概念
触发器(triggers):触发器包含调度逻辑,描述一个任务何时被触发,按日期或按时间间隔或按 cronjob 表达式三种方式触发。每个作业都有它自己的触发器,除了初始配置之外,触发器是完全无状态的。
作业存储器(job stores):作业存储器指定了作业被存放的位置,默认情况下作业保存在内存,也可将作业保存在各种数据库中,当作业被存放在数据库中时,它会被序列化,当被重新加载时会反序列化。作业存储器充当保存、加载、更新和查找作业的中间商。在调度器之间不能共享作业存储。
执行器(executors):执行器是将指定的作业(调用函数)提交到线程池或进程池中运行,当任务完成时,执行器通知调度器触发相应的事件。
调度器(schedulers):任务调度器,属于控制角色,通过它配置作业存储器、执行器和触发器,添加、修改和删除任务。调度器协调触发器、作业存储器、执行器的运行,通常只有一个调度程序运行在应用程序中,开发人员通常不需要直接处理作业存储器、执行器或触发器,配置作业存储器和执行器是通过调度器来完成的。
安装
pip install apscheduler
栗子:
# -*- coding: utf-8 -*-
from datetime import datetime
import os
from apscheduler.schedulers.blocking import BlockingScheduler
def tick():
print('Tick! The time is: %s' % datetime.now())
if __name__ == '__main__':
scheduler = BlockingScheduler()
scheduler.add_job(tick, 'interval', seconds=3)
print('Press Ctrl+{0} to exit'.format('Break' if os.name == 'nt' else 'C '))
try:
scheduler.start()
except (KeyboardInterrupt, SystemExit):
pass
运行结果:
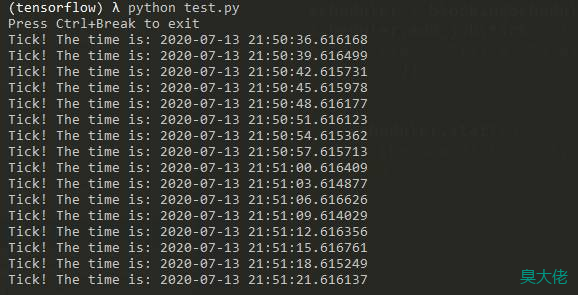
实例化一个 BlockingScheduler 类,不带参数表明使用默认的作业存储器-内存,默认的执行器是线程池执行器,最大并发线程数默认为 10 个(另一个是进程池执行器)。
添加一个作业 tick,触发器为 interval,每隔 3 秒执行一次,另外的触发器为 date,cron。date 按特定时间点触发,cron 则按固定的时间间隔触发。
加入捕捉用户中断执行和解释器退出异常,pass 关键字,表示什么也不做。
定时 cron 任务也非常简单:
# -*- coding: utf-8 -*-
from datetime import datetime
import os
from apscheduler.schedulers.blocking import BlockingScheduler
def tick():
print('Tick! The time is: %s' % datetime.now())
if __name__ == '__main__':
scheduler = BlockingScheduler()
scheduler.add_job(tick, 'cron', hour=19, minute=23)
print('Press Ctrl+{0} to exit'.format('Break' if os.name == 'nt' else 'C '))
try:
scheduler.start()
except (KeyboardInterrupt, SystemExit):
pass
直接给触发器 trigger 传入 ‘cron’ 即可。hour =19 ,minute =23 这里表示每天的19:23 分执行任务。这里可以填写数字,也可以填写字符串
hour =19 , minute =23
hour ='19', minute ='23'
minute = '*/3' 表示每 5 分钟执行一次
hour ='19-21', minute= '23' 表示 19:23、 20:23、 21:23 各执行一次任务
配置调度器
调度器的主循环其实就是反复检查是不是有到时需要执行的任务,分以下几步进行:
询问自己的每一个作业存储器,有没有到期需要执行的任务,如果有,计算这些作业中每个作业需要运行的时间点,如果时间点有多个,做 coalesce 检查。
提交给执行器按时间点运行。
在配置调度器前,我们首先要选取适合我们应用环境场景的调度器,存储器和执行器。下面是各调度器的适用场景:
- BlockingScheduler:适用于调度程序是进程中唯一运行的进程,调用start函数会阻塞当前线程,不能立即返回。
- BackgroundScheduler:适用于调度程序在应用程序的后台运行,调用start后主线程不会阻塞。
- AsyncIOScheduler:适用于使用了asyncio模块的应用程序。
- GeventScheduler:适用于使用gevent模块的应用程序。
- TwistedScheduler:适用于构建Twisted的应用程序。
- QtScheduler:适用于构建Qt的应用程序。
上述调度器可以满足我们绝大多数的应用环境,本文以两种调度器为例说明如何进行调度器配置。
作业存储器的选择有两种:一是内存,也是默认的配置;二是数据库。具体选哪一种看我们的应用程序在崩溃时是否重启整个应用程序,如果重启整个应用程序,那么作业会被重新添加到调度器中,此时简单的选取内存作为作业存储器即简单又高效。但是,当调度器重启或应用程序崩溃时您需要您的作业从中断时恢复正常运行,那么通常我们选择将作业存储在数据库中,使用哪种数据库通常取决于为在您的编程环境中使用了什么数据库。我们可以自由选择,PostgreSQL 是推荐的选择,因为它具有强大的数据完整性保护。
同样的,执行器的选择也取决于应用场景。通常默认的 ThreadPoolExecutor 已经足够好。如果作业负载涉及CPU 密集型操作,那么应该考虑使用 ProcessPoolExecutor,甚至可以同时使用这两种执行器,将ProcessPoolExecutor 行器添加为二级执行器。
apscheduler 提供了许多不同的方法来配置调度器。可以使用字典,也可以使用关键字参数传递。首先实例化调度程序,添加作业,然后配置调度器,获得最大的灵活性。
如果调度程序在应用程序的后台运行,选择 BackgroundScheduler,并使用默认的 jobstore 和默认的executor,则以下配置即可:
from apscheduler.schedulers.background import BackgroundScheduler
scheduler = BackgroundScheduler()
假如我们想配置更多信息:设置两个执行器、两个作业存储器、调整新作业的默认值,并设置不同的时区。下述三个方法是完全等同的。
配置需求
- 配置名为“mongo”的MongoDBJobStore作业存储器
- 配置名为“default”的SQLAlchemyJobStore(使用SQLite)
- 配置名为“default”的ThreadPoolExecutor,最大线程数为20
- 配置名为“processpool”的ProcessPoolExecutor,最大进程数为5
- UTC作为调度器的时区
- coalesce默认情况下关闭
- 作业的默认最大运行实例限制为3
方法一
from pytz import utc
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.jobstores.mongodb import MongoDBJobStore
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
from apscheduler.executors.pool import ThreadPoolExecutor, ProcessPoolExecutor
jobstores = {
'mongo': MongoDBJobStore(),
'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')
}
executors = {
'default': ThreadPoolExecutor(20),
'processpool': ProcessPoolExecutor(5)
}
job_defaults = {
'coalesce': False,
'max_instances': 3
}
scheduler = BackgroundScheduler(jobstores=jobstores, executors=executors, job_defaults=job_defaults, timezone=utc)
方法二
from apscheduler.schedulers.background import BackgroundScheduler
scheduler = BackgroundScheduler({
'apscheduler.jobstores.mongo': {
'type': 'mongodb'
},
'apscheduler.jobstores.default': {
'type': 'sqlalchemy',
'url': 'sqlite:///jobs.sqlite'
},
'apscheduler.executors.default': {
'class': 'apscheduler.executors.pool:ThreadPoolExecutor',
'max_workers': '20'
},
'apscheduler.executors.processpool': {
'type': 'processpool',
'max_workers': '5'
},
'apscheduler.job_defaults.coalesce': 'false',
'apscheduler.job_defaults.max_instances': '3',
'apscheduler.timezone': 'UTC',
})
方法三
from pytz import utc
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
from apscheduler.executors.pool import ProcessPoolExecutor
jobstores = {
'mongo': {'type': 'mongodb'},
'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')
}
executors = {
'default': {'type': 'threadpool', 'max_workers': 20},
'processpool': ProcessPoolExecutor(max_workers=5)
}
job_defaults = {
'coalesce': False,
'max_instances': 3
}
scheduler = BackgroundScheduler()
# .. do something else here, maybe add jobs etc.
以上涵盖了大多数情况的调度器配置,在实际运行时可以试试不同的配置会有怎样不同的效果。
启动调度器
启动调度器前需要先添加作业,有两种方法向调度器添加作业:一是通过接口add_job(),二是通过使用函数装饰器,其中 add_job() 返回一个apscheduler.job.Job类的实例,用于后续修改或删除作业。
我们可以随时在调度器上调度作业。如果在添加作业时,调度器还没有启动,那么任务将不会运行,并且第一次运行时间在调度器启动时计算。
注意:如果使用的是序列化作业的执行器或作业存储器,那么要求被调用的作业(函数)必须是全局可访问的,被调用的作业的参数是可序列化的,作业存储器中,只有 MemoryJobStore 不会序列化作业。执行器中,只有ProcessPoolExecutor 将序列化作业。
启用调度器只需要调用调度器的 start() 方法,下面分别使用不同的作业存储器来举例说明:
使用默认的作业存储器:
# coding:utf-8
from apscheduler.schedulers.blocking import BlockingScheduler
import datetime
from apscheduler.jobstores.memory import MemoryJobStore
from apscheduler.executors.pool import ThreadPoolExecutor, ProcessPoolExecutor
def my_job(id='my_job'):
print(id, '-->', datetime.datetime.now())
jobstores = {
'default': MemoryJobStore()
}
executors = {
'default': ThreadPoolExecutor(20),
'processpool': ProcessPoolExecutor(10)
}
job_defaults = {
'coalesce': False,
'max_instances': 3
}
scheduler = BlockingScheduler(jobstores=jobstores, executors=executors, job_defaults=job_defaults)
scheduler.add_job(my_job, args=['job_interval', ], id='job_interval', trigger='interval', seconds=5,
replace_existing=True)
scheduler.add_job(my_job, args=['job_cron', ], id='job_cron', trigger='cron', month='7-8,11-12', hour='7-11',
second='*/10', end_date='2020-07-30')
scheduler.add_job(my_job, args=['job_once_now', ], id='job_once_now')
scheduler.add_job(my_job, args=['job_date_once', ], id='job_date_once', trigger='date', run_date='2020-07-14 07:48:05')
try:
scheduler.start()
except SystemExit:
print('exit')
exit()
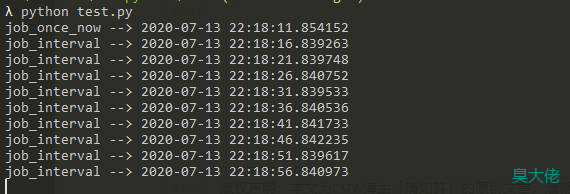
上述代码使用内存作为作业存储器,操作比较简单,重启程序相当于第一次运行。
使用数据库作为存储器:
# coding:utf-8
from apscheduler.schedulers.blocking import BlockingScheduler
import datetime
from apscheduler.jobstores.memory import MemoryJobStore
from apscheduler.executors.pool import ThreadPoolExecutor, ProcessPoolExecutor
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
def my_job(id='my_job'):
print(id, '-->', datetime.datetime.now())
jobstores = {
'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')
}
executors = {
'default': ThreadPoolExecutor(20),
'processpool': ProcessPoolExecutor(10)
}
job_defaults = {
'coalesce': False,
'max_instances': 3
}
scheduler = BlockingScheduler(jobstores=jobstores, executors=executors, job_defaults=job_defaults)
scheduler.add_job(my_job, args=['job_interval',],id='job_interval',trigger='interval', seconds=5,replace_existing=True)
scheduler.add_job(my_job, args=['job_cron', ], id='job_cron', trigger='cron', month='7-8,11-12',hour='7-11',second='*/10',end_date='2020-07-30')
scheduler.add_job(my_job, args=['job_once_now', ], id='job_once_now')
scheduler.add_job(my_job, args=['job_date_once', ], id='job_date_once', trigger='date', run_date='2020-07-14 07:48:05')
try:
scheduler.start()
except SystemExit:
print('exit')
exit()

说明:misfire_grace_time,假如一个作业本来 08:00 有一次执行,但是由于某种原因没有被调度上,现在 08:01 了,这个 08:00 的运行实例被提交时,会检查它预订运行的时间和当下时间的差值(这里是1分钟),大于我们设置的 30 秒限制,那么这个运行实例不会被执行。最常见的情形是 scheduler 被 shutdown 后重启,某个任务会积攒了好几次没执行如 5 次,下次这个作业被提交给执行器时,执行 5 次。设置 coalesce=True 后,只会执行一次。
其他操作如下:
scheduler.remove_job(job_id, jobstore=None) # 删除作业
scheduler.remove_all_jobs(jobstore=None) # 删除所有作业
scheduler.pause_job(job_id, jobstore=None) # 暂停作业
scheduler.resume_job(job_id, jobstore=None) # 恢复作业
scheduler.modify_job(job_id, jobstore=None, **changes) # 修改单个作业属性信息
scheduler.reschedule_job(job_id, jobstore=None, trigger=None, **trigger_args) # 修改单个作业的触发器并更新下次运行时间
scheduler.print_jobs(jobstore=None, out=sys.stdout) # 输出作业信息
调度器事件监听
scheduler 的基本应用,在前面已经介绍过了,但仔细思考一下:如果程序有异常抛出会影响整个调度任务吗?
任何代码都可能抛出异常,关键是,发生导常事件,如何第一时间知道,这才是我们最关心的,apscheduler 已经为我们想到了这些,提供了事件监听来解决这一问题。
将代码稍做调整,加入日志记录和事件监听,如下所示。
# coding:utf-8
from apscheduler.schedulers.blocking import BlockingScheduler
from apscheduler.events import EVENT_JOB_EXECUTED, EVENT_JOB_ERROR
import datetime
import logging
logging.basicConfig(level=logging.INFO,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
datefmt='%Y-%m-%d %H:%M:%S',
filename='log1.txt',
filemode='a')
def aps_test(x):
print(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'), x)
def date_test(x):
print(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'), x)
print(1 / 0)
def my_listener(event):
if event.exception:
print('任务出错了!!!!!!')
else:
print('任务照常运行...')
scheduler = BlockingScheduler()
scheduler.add_job(func=date_test, args=('一次性任务,会出错',),
next_run_time=datetime.datetime.now() + datetime.timedelta(seconds=15), id='date_task')
scheduler.add_job(func=aps_test, args=('循环任务',), trigger='interval', seconds=3, id='interval_task')
scheduler.add_listener(my_listener, EVENT_JOB_EXECUTED | EVENT_JOB_ERROR)
scheduler._logger = logging
scheduler.start()
说明:
第 7-11 行配置日志记录信息,日志文件在当前路径,文件名为 “log1.txt”。
第 35 行启用 scheduler 模块的日记记录。
第 23-27 定义一个事件监听,出现意外情况打印相关信息报警。
运行结果如下所示。
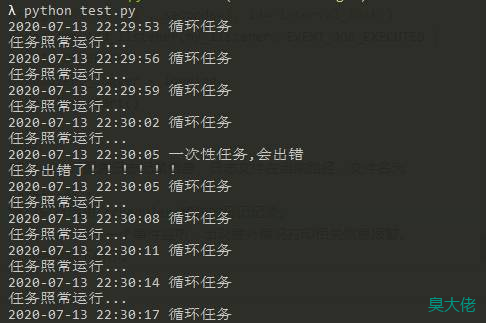
在生产环境中,可以把出错信息换成发送一封邮件或者发送一个短信,这样定时任务出错就可以立马就知道。
————————————————
版权声明:本文为CSDN博主「清如許」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/somezz/article/details/83104368
本文链接:https://choudalao.com/article/166
转载请注明来源,感谢尊重原创内容。
留言评论
支持表情、回复和点赞。评论需要先登录。