csv文本文件存储数据 | 臭大佬
csv文本文件存储数据
CSV 文件
CSV 文件全称为逗号分隔值(Comma-Separated Values)文件,在通常形式下,其是由英文逗号作为分隔符(可以根据需要来变化)的纯文本组成的文件。CSV 文件由行和列组成,可以比较方便的在不同应用之间迁移数据。我们可以使用普通的文本编辑器将其打开,同样也能够使用Excel 等表格文件将其打开为表格形式。
csv 模块基本操作
将打开的 csv 文件传入 csv 模块的 reader()方法中,生成一个 csv 的 reader 对象,可以进行遍历操作。
将打开的csv文件传入csv模块的writer()方法中,生成一个csv的writer对象,可以使用writerow()方法按行写入数据:
import csv
def csv_write(fileName, data):
'''
写入
:param fileName:
:param data:
:return:
'''
with open(fileName, 'w', encoding='utf8', newline='') as file:
file_write = csv.writer(file, delimiter=',')
file_write.writerow(data)
def csv_reader(fileName):
'''
读取
:param fileName:
:return:
'''
with open(fileName, 'r') as file:
csvfile = csv.reader(file)
for r in csvfile:
print(r)
if __name__ == '__main__':
fileName = 'dtd.csv'
data = ['s', 'e']
csv_write(fileName, data)
csv_reader(fileName)

csv 模块还提供了以字典形式来进行读写。
csv.DictReader()和csv.DictWriter()方法:接受一个文件对象
import csv
def csv_write(fileName, fieldnames, data):
'''
:param fileName:
:param data:
:return:
'''
with open(fileName, 'w', encoding='utf8', newline='') as file:
csvfile = csv.DictWriter(file, fieldnames=fieldnames)
# 写入 csv 文件列名
csvfile.writeheader()
# 写入行数据
csvfile.writerow(data)
def csv_reader(fileName):
'''
:param fileName:
:return:
'''
with open(fileName) as file:
csvfile = csv.DictReader(file)
for row in csvfile:
print(row['first_name'], row['last_name'])
if __name__ == '__main__':
fileName = 'test.csv'
fieldnames = ['first_name', 'last_name']
dic = {'first_name': 'aaa', 'last_name': 'bbb'}
csv_write(fileName, fieldnames, dic)
csv_reader(fileName)
栗子
# coding:utf-8
# 引入相关模块
import requests
from bs4 import BeautifulSoup
import csv
url = "http://house.366300.com/houselist.asp?type=sale"
# 请求腾讯新闻的 URL,获取其 text 文本
wbdata = requests.get(url)
wbdata.encoding = 'gbk' # 将编码格式改为utf-8
# 对获取到的文本进行解析
soup = BeautifulSoup(wbdata.text, 'lxml')
# 从解析文件中通过 select 选择器定位指定的元素,返回一个列表
ids = soup.select(
"table.bk > tr> td:nth-child(2)> table:nth-child(4)>tr>td>table>tr>td>table>tr>td>table>tr>td:nth-child(1)>div>p>font>span")
areas = soup.select(
"table.bk > tr> td:nth-child(2)> table:nth-child(4)>tr>td>table>tr>td>table>tr>td>table>tr>td:nth-child(2)>div>span")
address = soup.select(
"table.bk > tr> td:nth-child(2)> table:nth-child(4)>tr>td>table>tr>td>table>tr>td>table>tr>td:nth-child(3)>div>span>a>font")
types = soup.select(
"table.bk > tr> td:nth-child(2)> table:nth-child(4)>tr>td>table>tr>td>table>tr>td>table>tr>td:nth-child(4)>div>span")
prices = soup.select(
"table.bk > tr> td:nth-child(2)> table:nth-child(4)>tr>td>table>tr>td>table>tr>td>table>tr>td:nth-child(5)>div>span")
times = soup.select(
"table.bk > tr> td:nth-child(2)> table:nth-child(4)>tr>td>table>tr>td>table>tr>td>table>tr>td:nth-child(6)>div>span")
dict = {}
for i in range(len(ids)):
if len(ids) > 30:
id_i = i + 1
else:
id_i = i
if len(areas) > 30:
area_i = i + 1
else:
area_i = i
if len(address) > 30:
addres_i = i + 1
else:
addres_i = i
if len(types) > 30:
type_i = i + 1
else:
type_i = i
if len(prices) > 30:
price_i = i + 1
else:
price_i = i
if len(times) > 30:
time_i = i + 1
else:
time_i = i
id = ids[id_i].get_text().strip()
area = areas[area_i].get_text().strip()
addres = address[addres_i].get_text().strip()
type = types[type_i].get_text().strip()
price = prices[price_i].get_text().strip()
time = times[time_i].get_text().strip()
data = {
'id': id,
'area': area,
'addres': addres,
'type': type,
'price': price,
'time': time,
}
dict[i] = []
dict[i].append(data)
with open('listings.csv', 'a+', encoding='utf-8') as files:
csvfile = csv.writer(files)
data = ['编号', '区域', '地点', '类型', '价格', '发布时间']
csvfile.writerow(data)
# 对返回的列表进行遍历
for n in dict:
data = [dict[n][0]['id'], dict[n][0]['area'], dict[n][0]['addres'], dict[n][0]['type'], dict[n][0]['price'],dict[n][0]['time']]
csvfile.writerow(data)
运行结果: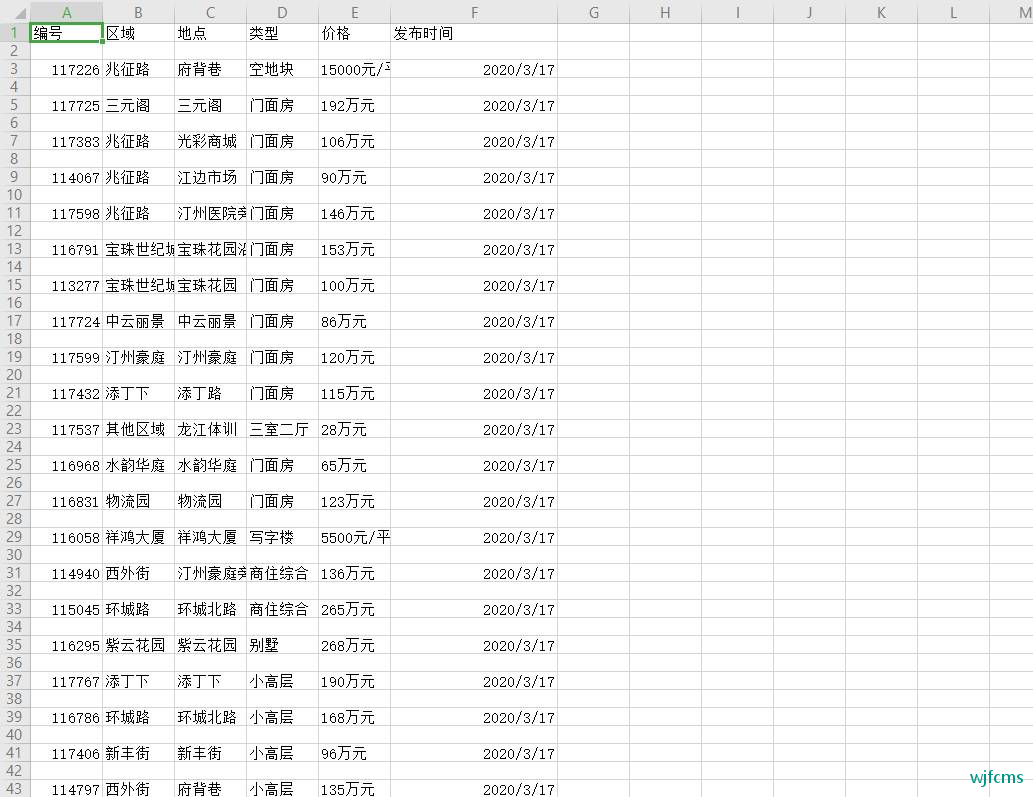
有木有看到,小小县城房价也是高的很啊!!
本文链接:https://choudalao.com/article/126
转载请注明来源,感谢尊重原创内容。
留言评论
支持表情、回复和点赞。评论需要先登录。